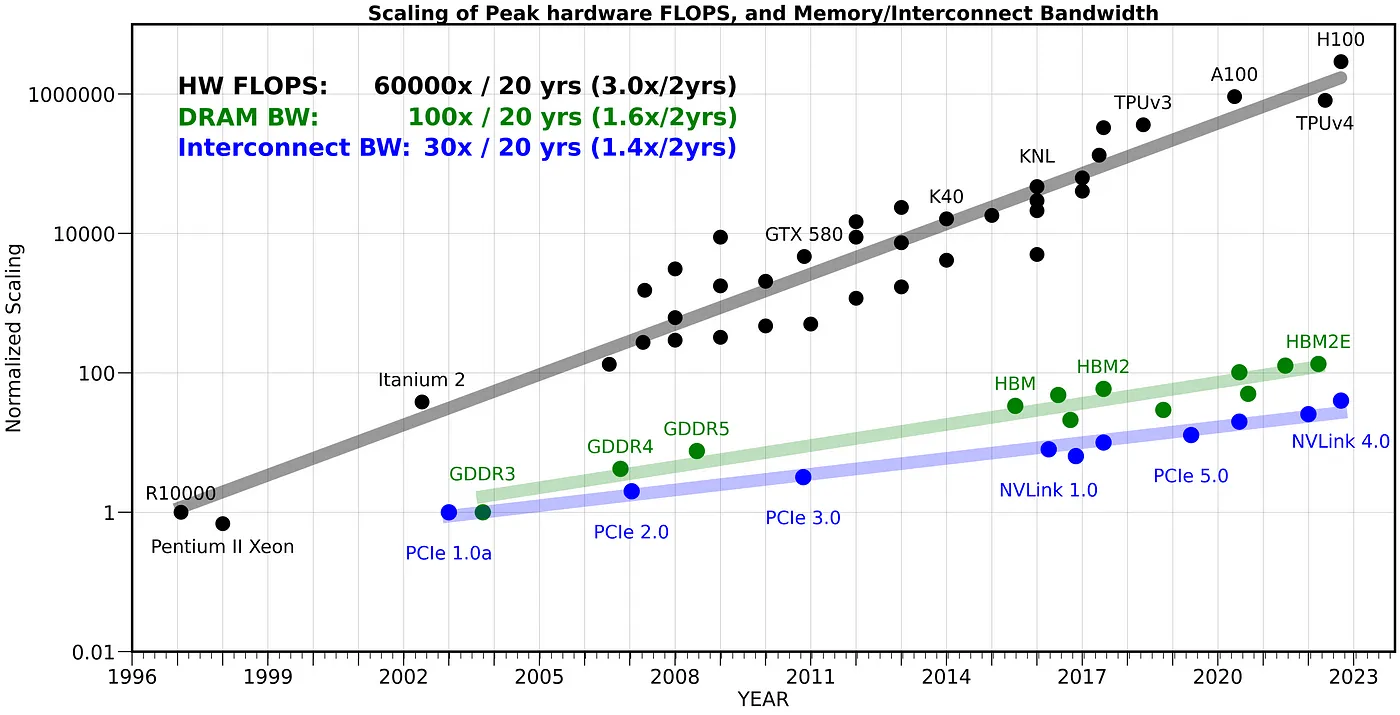
In the past few years, hardware computing power roughly triples every two years, whereas communication bandwidth only increases by 1.4 times as is shown in the figure below. The impact of this gap becomes increasingly pronounced in large-scale training tasks. For instance, when training LLMs on H100 clusters, the communication overhead typically accounts for a higher percentage. In such scenarios, communication can easily become the bottleneck for system performance.
In this blog, I’ll talk about how people are handling this now. Specifically, we’ll talk about the paper in [2].
It focuses on a very practical systems problem in large-scale LLM training and inference:
GPU communication becomes the bottleneck when scaling tensor parallelism.
The authors propose a new runtime/kernel design called FLUX that overlaps communication and computation much more aggressively than existing systems.
Communication Challenges
When training or serving large models across many GPUs, each GPU only holds part of the tensors. That means GPUs constantly need to exchange data using operations like:
- AllReduce
- ReduceScatter
- AllGather
This communication happens through either
- NVLink (within node)
- InfiniBand / PCIe / Ethernet (across nodes).
For modern LLMs, matrix multiplications (GEMMs) are extremely optimized. Communication increasingly dominates runtime. The paper argues that existing systems overlap communication and compute only coarsely, leaving a lot of GPU idle time. The central idea is surprisingly elegant, instead of sequencing compute kernel then communication kernel they do many tiny compute+communication pieces fused together into one mega-kernel. This is the essence of FLUX.
Why existing overlap methods are limited
Traditional overlap looks like this:
GPU:
[compute chunk 1]
[sync]
[launch NCCL comm]
[compute chunk 2]
[sync]
[launch NCCL comm]
[wait]
Problems:
- kernel launch overhead
- synchronization barriers
- communication starts too late
- NCCL runs somewhat independently
- GPUs still idle frequently
The issue with the traditional approach is that it leaves performance on the table because the overlap is too coarse and synchronization-heavy.
We can think about GPUs and networks as assembly lines. We want:
- GPU compute units busy
- network links busy
- neither waiting for the other
Traditional overlap only partially achieves that.
The hidden problem: communication starts too late
Imagine chunk 1 compute takes:
4 ms
and communication takes:
3 ms
Timeline:
0----4----8 ms
Compute1
Comm1
Compute2
Communication cannot begin until chunk 1 fully completes. So the network sits idle during the first 4 ms. We get imperfect overlap.
The deeper issue: chunks are still too large
Traditional systems overlap at tensor/chunk granularity. But GPUs internally operate at:
- warp granularity
- tile granularity
- block granularity
A GEMM may process thousands of tiles internally. Yet NCCL waits for the entire chunk before sending anything. So there’s a huge delay between first tile becoming ready and communication starting. This is wasted opportunity. What FLUX changes? FLUX says why wait for the whole chunk? Now communication begins almost immediately. The network pipeline stays continuously full.
Compute tile 1
Immediately send tile 1
Compute tile 2
Send tile 2
Compute tile 3
Send tile 3
Another hidden problem: kernel launch overhead
Traditional flow:
launch compute kernel
launch NCCL kernel
launch compute kernel
launch NCCL kernel
Each launch has overhead:
- scheduling
- synchronization
- queueing
- stream coordination
Small individually, but huge at scale. FLUX removes much of this by using: one persistent fused kernel
Another problem: NCCL is semi-independent
Traditional setup:
compute stream
communication stream
The GPU scheduler tries to balance both. But:
- NCCL kernels consume SMs
- GEMMs consume SMs
- they interfere
- synchronization becomes coarse
Sometimes communication stalls compute, or compute stalls communication. Overlap becomes inconsistent.
Why GPUs hate synchronization barriers
Traditional chunking introduces barriers like:
finish chunk
sync
communicate
sync
continue
Modern GPUs are fastest when work streams continuously. Every synchronization:
- drains pipelines
- reduces occupancy
- hurts latency hiding
FLUX minimizes these barriers.
Partial readiness
The key insight is partial readiness. This is the core concept. Suppose tensor = 100 MB. Traditional NCCL, waits for all 100 MB. But internally first 1 MB may already be computed. FLUX communicates as soon as tiny portions are ready. This dramatically improves pipeline efficiency. Why this matters MORE for LLMs? Large LLM inference often has small batch sizes especially during decoding. Then compute gets smaller, communication latency dominates. Traditional overlap becomes weak because it chunks finish quickly, launches overhead becomes significant and synchronization dominates. FLUX helps because it pipelines at very fine granularity and keeps network continuously utilized.
The real bottleneck being attacked. Traditional systems suffer from pipeline bubbles. FLUX tries to achieve continuous utilization.
Example:
# Notice empty regions.
Compute: ████████
Comm: ████████
# no bubble
Compute: ████████████
Comm: ████████████
What FLUX does differently
FLUX:
- breaks computation into very small tiles
- breaks communication into tiny pieces
- interleaves them inside ONE fused GPU kernel
Conceptually:
for tile in tiles:
compute(tile)
send(tile)
receive(tile)
continue_compute(tile)
Instead of separate compute kernel and separate NCCL kernel, now everything becomes one persistent fused kernel.
This removes launch overhead, synchronization overhead and scheduling gaps. communication to happen continuously during compute
Two patterns in TP
Looking back at Figure 1 (the MLP forward pass), there are two communication points:
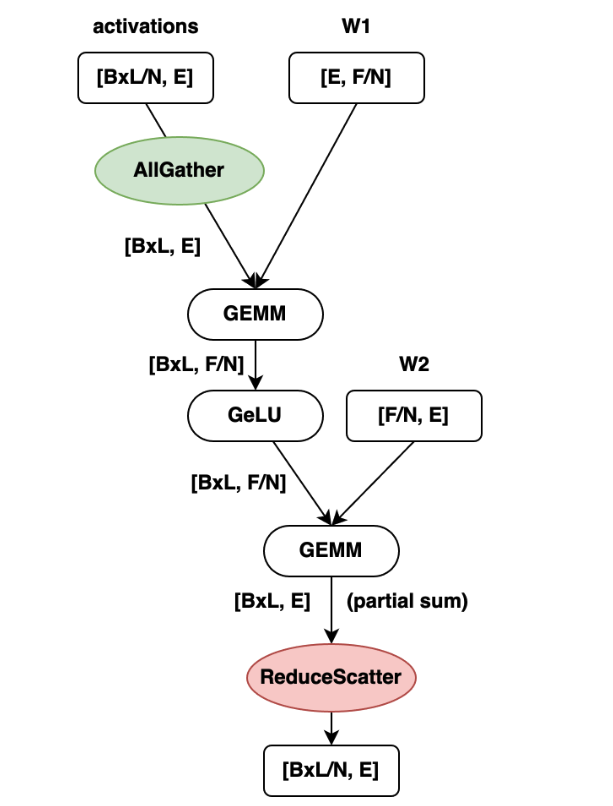 Figure 1. MLP
Figure 1. MLP- AllGather → GEMM (before the first GEMM): activations need to be gathered before matmul
- GEMM → ReduceScatter (after the second GEMM): partial sums need to be reduced and scattered
Flux fuses communication into the GEMM kernel in both cases, but at different points in the kernel:
| Pattern | Fusion point | What gets fused |
|---|---|---|
| GEMM + ReduceScatter | Epilogue (end of kernel) | The actual data send/write to remote GPUs happens as the GEMM tiles finish producing output |
| AllGather + GEMM | Prologue (start of kernel) | Only the wait-for-signal logic is fused; the data transfer itself runs asynchronously on the host side |
Why the asymmetry
For ReduceScatter (Algorithm 1): the GEMM produces the data that needs to be communicated. So once a tile of C is computed, the kernel can immediately write/send it to the destination GPU as part of the epilogue. Compute → communicate, fused naturally.
For AllGather (Algorithms 2 & 3): the GEMM consumes data that’s being communicated in. The kernel can’t send anything — it has to wait for input tiles to arrive. So Flux fuses only a WaitSignal spin in the prologue. Each threadblock waits for its input tile to be ready, then runs standard GEMM. Meanwhile, the host side issues async cudaMemcpy transfers (pull- or push-based) and sets signals as tiles land.
Because only the wait logic is fused on the AllGather side, AllGather doesn’t strictly require P2P — you can fall back to NCCL send/recv for the data movement. ReduceScatter fusion does need P2P (or NVSHMEM across nodes) since the kernel itself is doing the remote writes.
Where the exposed time shows up
- ReduceScatter: small unhidden tail at the end — the last tiles produced still have to finish their sends after GEMM compute is done
- AllGather: small unhidden head at the beginning — the first tiles’ waits can’t be hidden if data hasn’t arrived yet (though local tiles have signals preset to true, so there’s always some work warps can start on immediately)
In both cases, the bulk of communication is hidden inside the GEMM kernel via the GPU’s natural warp-level latency hiding — that’s the core insight versus the medium-grained chunked approach that splits GEMM into multiple smaller kernels.
The architecture pattern you should learn from
The paper is really teaching a broader systems principle: fine-grained pipelined execution is better than coarse staged execution. This appears everywhere now:
| Old style | New style |
|---|---|
| stage-by-stage | streaming pipeline |
| isolated kernels | fused kernels |
| bulk synchronization | incremental async progress |
| separate communication | communication embedded into compute |
- Stream communication earlier: Don’t wait for full tensor completion. Instead communicate tiles/chunks immediately. This is streaming tensor parallelism
- Persistent kernels: FLUX strongly suggests persistent execution models, long-lived kernels and avoiding repeated launches. This is increasingly critical on modern GPUs.
- Communication-aware scheduling: Most ML frameworks still optimize compute graphs, but future systems optimize compute + network jointly. This is where all training frameworks are all evolving.
- For inference systems overlapping communication continuously during token generation. Decoding is communication-sensitive because batch sizes shrink and communication latency dominates. FLUX helps precisely there.
If you write CUDA/Triton kernels
This paper is extremely valuable. You should study:
- tile scheduling
- async copy
- warp specialization
- persistent kernels
- software pipelining
The mental model becomes:
while true:
load next tile
compute current tile
communicate previous tile
This is basically GPU systems engineering at the frontier.
The very similar idea is explored in CODA [5] where the computation replaces the communication discussed in FLUX.
References
- AI and Memory Wall
- FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
- Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
- https://github.com/bytedance/flux
- CODA: Rewriting Transformer Blocks as GEMM-Epilogue Programs
- https://github.com/uccl-project/mKernel
- https://uccl-project.github.io/posts/mkernel/
...